:format(webp))
What an AI Agent Is — and how to build one that actually works for you
Read this and you'll come away with a clear map of what modern AI agents do, the parts that make them run, pitfalls to avoid, and practical choices you can make when you design one for your team or product.
What exactly is an AI agent?
An AI agent is a system that senses input, reasons about it, and takes actions to achieve goals without constant human direction. This general idea goes back to the concept of an “intelligent agent” in AI research — a program that perceives and acts within an environment ( Wikipedia’s definition of an intelligent agent ). Modern agentic systems usually combine a large language model (LLM) with modules for memory, planning, and external tool use.
Core components, explained
Most production agents share the same high-level pieces. Each has a clear role and trade-offs.
LLM (the reasoning core): handles language understanding, planning, and generating actions or queries. LLMs serve as the central reasoning engine in agentic systems.
Memory: short-term context (the conversation window) and long-term stores (vector databases or knowledge graphs) to retain facts across interactions.
Tools & function calls: connectors that let the agent read data, call APIs, run code, or control systems; function-calling APIs are a first-class pattern for safe tool access ( OpenAI function calling guide ).
Planning / controller: the agentic loop that decides which tools to use, when to consult memory, and when to ask a human for approval.
Observability, guardrails, and human-in-the-loop controls: telemetry, auditing, and approval gates to trace and constrain agent behavior in production-
Component | Role | Example/Tool |
|---|---|---|
LLM | Language understanding, planning, generating actions | OpenAI GPT-4 |
Memory | Short-term context windows, long-term stores | Vector DB, Knowledge Graphs |
Tools & function calls | API connectors, code execution | OpenAI Function Calling |
Planning/controller | Tool selection, memory usage, human approval | Custom Loop Controller |
Observability & guardrails | Telemetry, auditing, approval gates |
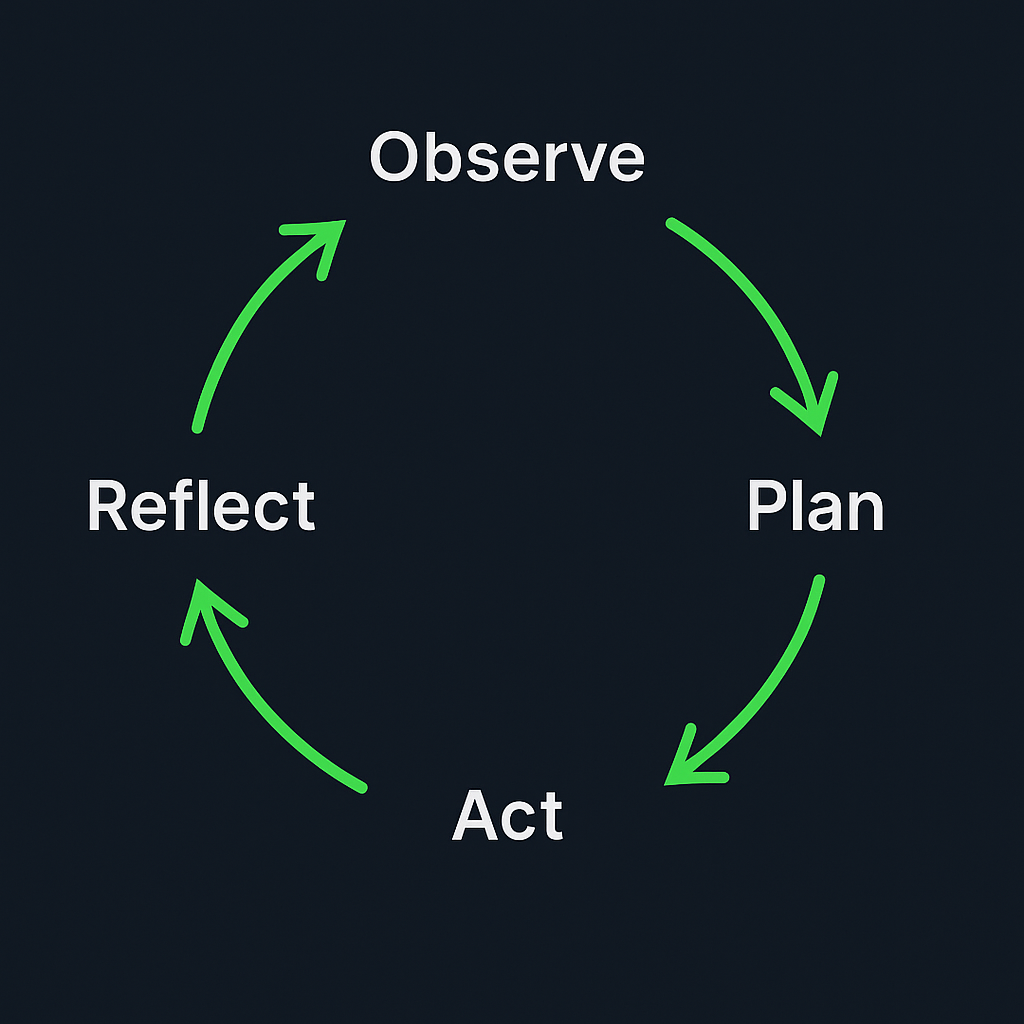
The agentic loop — observe, plan, act (and repeat)
At runtime an agent typically follows a loop:
Observe: gather input from user, sensors, or APIs.
Plan: use the LLM plus memory to form a plan or sequence of tool calls.
Act: execute tool calls or produce responses.
Reflect (optional): check outcomes, update memory, or re-plan.
This cycle is a practical version of classic control loops (e.g., OODA) and is central to frameworks that combine reasoning with actions.
Memory: short-term vs long-term — pick the right store
Short-term memory lives in the model context window (what you pass in a single prompt). Long-term memory is best kept outside the model in indexed stores:
Conversation buffers for immediate context.
Vector databases or embeddings for persistent retrieval.
Tools like LangChain and LlamaIndex show patterns for stitching retrieval into prompts so the agent stays informed.
Tool use and safe function-calling
Agents gain power by calling tools (APIs, databases, code). Function-calling APIs make this explicit and easier to monitor. OpenAI provides a formalized function-calling approach so the model returns structured calls you can validate and dispatch. Always validate inputs/outputs and run side-effecting actions behind approval or sandbox layers.
Grounding agents to avoid hallucination
LLMs can generate confident but false statements. To reduce that, use retrieval-augmented generation: fetch relevant documents or database rows, include them in the prompt, and ask the model to cite sources ( Retrieval-Augmented Generation (RAG) paper ). Practical tactics:
Use retrieval for factual answers and require source citations.
Re-score or verify model outputs against trusted APIs or databases.
Keep a human verification step for critical actions.
When multiple agents must work together
In enterprise settings you'll often have many agents or micro-agents collaborating. Multi-agent coordination covers communication, task allocation, and conflict resolution:
Coordination patterns include delegation hierarchies, shared memory buses, and negotiation protocols.
Research shows complex, emergent strategies can appear when agents interact in shared environments.
Design choices:
Define shared goals and conflict-resolution rules up front.
Use an arbitration controller or human overseer for high-risk decisions.
Log all inter-agent messages for later auditing.
Observability and interpretability — how you debug agents
Understanding why an agent chose a sequence of actions is critical:
Trace tool-call sequences, intermediate model responses, and retrieved documents.
Record prompts, model logits or confidence signals when available, and downstream side effects.
Use chain-of-thought or explicit reasoning traces to surface the model’s rationale.
Observability platforms for ML pipelines help spot regressions and data drift in deployed agents.
Cost control: how agent complexity affects spend
Agentic systems increase API calls, token usage, and compute overhead. Common levers to control cost:
Route inexpensive tasks to smaller, cheaper models and reserve large models for hard reasoning.
Cache retrieval results and repeated tool outputs.
Use conditional computation or Mixture-of-Experts patterns to activate heavier models only when necessary.
Measure cost per action and instrument billing so you can optimize the most expensive paths first.
Lever | Description |
|---|---|
Route to smaller models | Direct inexpensive tasks to cheaper models; reserve large models for complex reasoning |
Cache results | Store retrieval and tool outputs to avoid repeated API calls |
Conditional computation | Use Mixture-of-Experts or conditional model activation for heavy tasks |
Safety and guardrails — keeping agents within bounds
Agents can propose harmful or risky actions unless constrained. Practical guardrails:
Implement policy checks and allow/deny lists for tool calls.
Require human approval for irreversible actions.
Use alignment techniques to guide model behavior.
Combine automated policy enforcement with human oversight for high-value or safety-critical domains.
Emergent behavior and unexpected interactions
When agents learn or are composed together, unexpected strengths and weaknesses can appear. The LLM literature documents “emergent abilities” that show up only at certain model scales. That means:
Test agent combinations thoroughly in representative scenarios.
Start with constrained tool sets and increase complexity gradually.
Add monitoring for out-of-distribution behavior and rollback mechanisms.
Specialization vs generalization — how to choose
You can design agents as specialists (optimized for one domain) or generalists (broad capabilities):
Specialist agents are cheaper, more reliable for narrow tasks, and easier to verify.
Generalist agents can handle diverse queries but may require heavier safeguards and more compute.
A hybrid approach often works best: route domain-specific tasks to specialist agents and keep a generalist coordinator for triage.
Real-time vs batch agent processing — fit to the use case
Agents designed for immediate user interactions (real-time) require low-latency, synchronous pipelines and often smaller models. Asynchronous or batch agents can run heavier reasoning steps offline and handle large backlogs (e.g., nightly analysis or bulk data enrichment). See the AWS batch processing overview for details on trade-offs between synchronous and batch patterns.
Tooling and frameworks that will speed you up
Use existing agent frameworks to avoid reinventing core plumbing:
LangChain for orchestration and prompt patterns.
LlamaIndex for building retrieval layers and connecting knowledge stores.
Vector databases (Pinecone, Milvus, Weaviate) for scalable retrieval — choose based on latency and workload requirements.
Quick checklist for building a reliable agent
Define goal and failure modes.
Select an LLM and cheaper fallback models.
Add retrieval and long-term memory for facts.
Expose tools through validated, auditable APIs.
Implement guardrails and human approval for risky actions.
Add observability: logs, traces, and metrics.
Test with adversarial and edge-case scenarios.
Monitor costs and iterate.

Where to take this next
If you’re ready to move from idea to prototype, start with a minimal agent: one small model for routine text handling, one retrieval index for grounding, and a single, audited API for a side effect (e.g., create a calendar event). Instrument everything from day one so you can learn fast and keep control.
:format(webp))
:format(webp))
:format(webp))