:format(webp))
How to Build an AI-Agent Content Operations System That Actually Runs at Scale
In this guide you’ll get a practical, end-to-step picture of how AI agents can own parts of your content lifecycle — from topic discovery to continuous updates — and which production practices make that safe, observable, and repeatable.
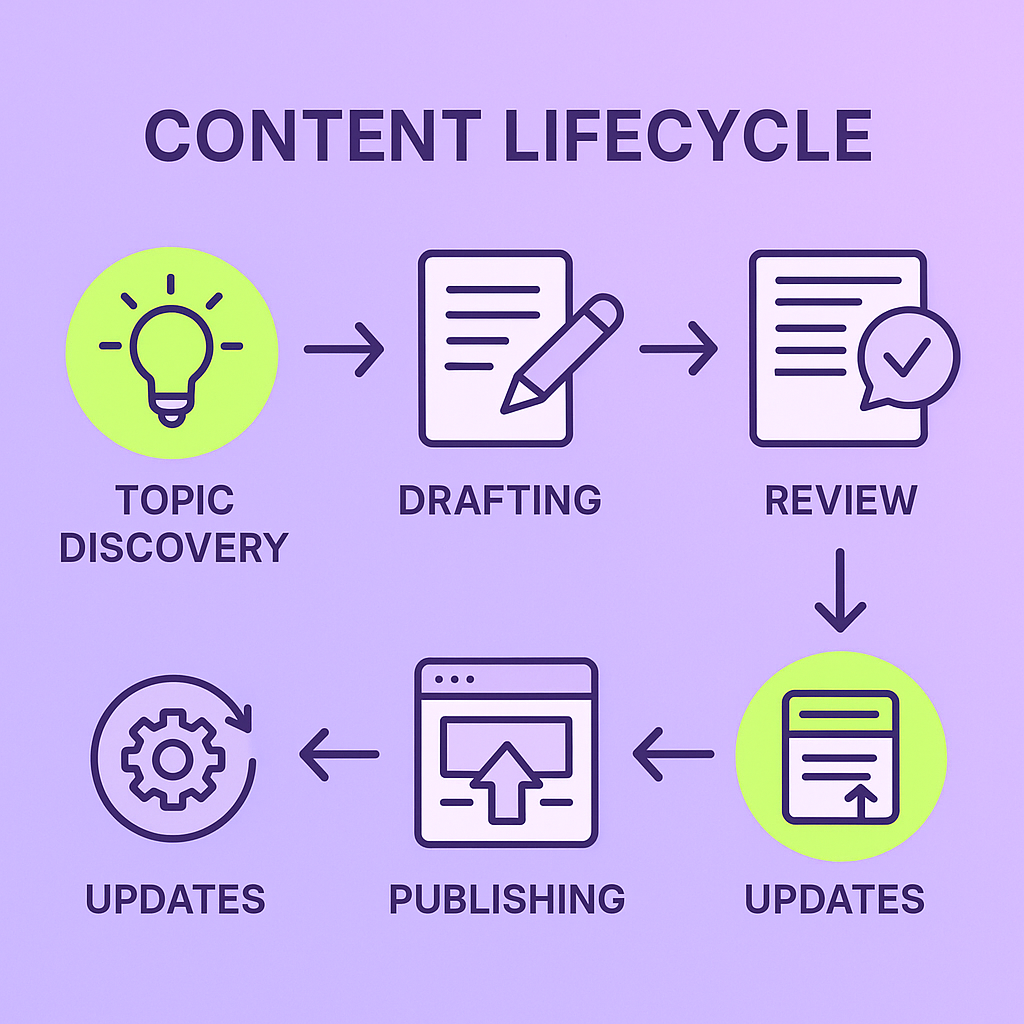
What AI agents do across the content lifecycle
AI agents are intelligent software entities that perceive input, take actions (like generating or scheduling content), and report outcomes. In content operations they commonly help with:
research (topic discovery, keyword analysis, competitor signals) — see how agents gather and synthesize web and analytics data with Retrieval-Augmented Generation (RAG)
drafting (outline generation, first drafts, variants) — many agent frameworks support templates and few-shot guidance for consistent drafts ( LangChain agents docs )
review & update (SEO audits, freshness checks, content repurposing) — you can automate score-based audits and create update tasks for humans.
publishing & distribution (scheduling, cross-channel posting, personalization) — agents can call platform APIs to post and adapt content per channel (APIs such as those common in content platforms and social schedulers)
Content Operation | Agent Action | Key Benefit |
|---|---|---|
Research | Gather and synthesize web and analytics data using Retrieval-Augmented Generation (RAG) | In-depth insights from web and competitor signals |
Drafting | Generate outlines, first drafts, and variants with templates and few-shot guidance | Rapid production of consistent, high-quality drafts |
Review & Update | Automate SEO audits, freshness checks, and create update tasks | Maintains content quality and SEO optimization |
Publishing & Distribution | Schedule, post across channels, personalize via platform APIs | Efficient, targeted, cross-channel dissemination |
For the research and retrieval, Hugging Face’s RAG documentation shows how flows let agents fetch domain evidence without retraining models, which is critical for accuracy and timely context.
Designing agent roles that match real tasks
Instead of one giant “content AI,” split responsibilities into task-specific agents. Typical roles:
Research agent: pulls SERP data, trending signals, and internal analytics
Outline agent: converts research into a structured brief and headings
Draft agent: writes first drafts and variations per tone/length
SEO auditor agent: scores and suggests on-page optimizations
Publishing agent: schedules, localizes, and posts across channels
Agent Role | Function |
|---|---|
Research agent | Pulls SERP data, trending signals, and internal analytics. |
Outline agent | Converts research into a structured brief and headings. |
Draft agent | Writes first drafts and variations per tone and length. |
SEO auditor agent | Scores and suggests on-page optimizations. |
Publishing agent | Schedules, localizes, and posts content across channels. |
This modular approach maps onto common enterprise needs and helps with governance and traceability ( multi-agent systems overview ).
Why modular agents beat one-size-fits-all
Separate agents make it easier to:
Version and test one capability at a time (e.g., experiment with a new prompt for outlines).
Escalate to human review only when a defined threshold is breached (reduces false positives).
Reuse specialized agents across many pipelines (e.g., the SEO auditor can work for blog posts and landing pages).
From prototype to production: AgentOps and CI/CD for content agents
If you want agents to run reliably at scale, you need production practices similar to ML/ModelOps. Key capabilities:
model and prompt versioning so you can roll back or A/B test controlled changes
CI/CD pipelines for prompt changes, tests, and deployment
observability for runs, costs, and failure modes
Platforms are adding features to manage these operational needs. If you’re building your own stack, borrow patterns from MLOps: automated tests, staging environments, and continuous evaluation of agent outputs before pushing to production.
Orchestrating complex flows with graph-based tools (LangGraph and friends)
When multiple agents must coordinate (research → outline → draft → SEO audit → publish), graph-based orchestration is useful. Tools that express workflows as nodes and edges make it easier to:
visualize dependencies and data flow
run planning-execution-reflection cycles (plan what to do, execute steps, reflect on outcomes and adapt)
Graph approaches also simplify adding conditional logic (for example, route to human review if the SEO score is below threshold).
Autonomy metrics: how to measure agent value and risk
You need metrics beyond "content published." Useful KPIs include:
autonomy score: percent of runs completed end-to-end without human intervention (derived from run logs)
escalation rate: percent of runs sent to humans for review or correction
cost-per-run: cloud/compute + API usage costs divided by successful outputs
outcome success rate: task-specific success (e.g., draft accepted as-is, or improved SEO by X points)
You can implement these using evaluation frameworks that capture pass/fail for tasks; see OpenAI Evals for an example of how to standardize checks and grade outputs automatically.
Continuous content learning without heavy retraining
You don’t need to retrain models every time your audience or brand voice shifts. Instead, use cyclical feedback loops where agents:
perceive results (engagement metrics, human edits, SEO changes),
reason about needed changes (e.g., update prompt, add new retrieval docs),
act (apply updated prompts, push revised drafts),
learn (log outcomes and update scoring rules).
Hierarchical multi-agent setups for large teams and global content
For enterprise content demands, design agent hierarchies:
top-level coordinator agent: plans the campaign and assigns sub-agents
functional sub-agents: SEO auditor, translate/localize agent, compliance checker
execution agents: drafting, formatting, publishing
This structure makes it easy to enforce brand rules and compliance (the compliance checker can block or flag content before publishing) and to localize content without re-running the entire pipeline.
Human-in-the-loop: where people should be involved
Keep humans in the loop for:
final quality checks on high-stakes content (legal, product safety)
tuning guardrails and reviewing high escalation-rate flows
strategic tasks like content calendars and campaign planning
Use human feedback signals to update scoring and prompt templates. Capture edits in structured logs to feed your continuous learning loop and to build an audit trail.
Practical implementation checklist
Map your content lifecycle and assign agent roles.
Prototype a simple RAG + draft agent flow for one content type.
Add evaluation tests for outputs (use an eval framework).
Add CI/CD and versioning for prompts and models (prompt registries help).
Introduce a graph-based orchestrator for multi-step processes.
Instrument autonomy and escalation metrics; iterate where escalation is high.
Implement guardrails and human review for sensitive content.
Risks and governance you must plan for
hallucinations and factual errors — use RAG and ask agents to cite sources; verify with human review for critical claims
bias and compliance issues — run automated compliance checks and store audit logs
cost runaway — monitor cost-per-run and set budgets/quotas on production agents
version drift — keep prompt and model versioning in CI/CD so you can roll back
Wrap-up: What you should do first
Start with one repeatable content flow (for example, research → outline → draft → publish) and make it observable: log every run, track autonomy and escalation, and add a simple human approval gate. From there, add agent orchestration, AgentOps practices (versioned prompts and CI/CD), and autonomy metrics to expand safely.
Want support for Custom AI Agents?
See our custom AI agent offering and reach out on demand.
Custom AI Agent Development:format(webp))
:format(webp))
:format(webp))